

Fix the root cause of No-Call No-Show with help from TeamSense
At TeamSense, our journey to create a robust and scalable attendance management platform wasn't just about building software—it was about architecting a future. We envisioned a system capable of handling rapid growth and evolving user needs, with a solid foundation for innovation as crucial as speed.
Strategic Beginnings and a Hybrid Proof of Concept
We began with strategic planning and an in-depth proof-of-concept (POC) phase. We explored various technologies, including Golang, Rust, and C#, each offering unique advantages. Our POC culminated in a hybrid approach: blending our existing monolith with serverless functions dedicated to Tier-1 services. This strategy allowed us to enhance, modernize, and strategically integrate LLM capabilities into our core functionality.
Our Core Platform Principles: A Blueprint for Scalability
To guide our development and ensure long-term success, we established these core platform principles as the bedrock of our architecture:
- Generic yet Customizable: The platform provides a generic foundation that caters to diverse customers while enabling easy customization.
- Data as Platform: We prioritize data integrity, isolation, and accessibility, ensuring all data is discoverable, understandable, secure, trustworthy, and reliable.
- LLM Awareness: Our platform, services, workflows, and APIs integrate with LLMs to provide customers with intelligent recommendations and knowledge-driven capabilities.
- Data Contracts: Clear data contracts maintain consistency by defining structure, schema, data fidelity, and security requirements.
- Evolvable Designs: Our services and designs adapt to change, enabling updates without disruption while maintaining focus on ecosystem-wide solutions. (inspired by Dr. Werner Vogels’ Monoliths are not Dinosaurs)
- Standards, Performance, and Security: We prioritize security through standardized APIs and logging protocols, while ensuring optimal performance through comprehensive Continuous Integration/Continuous Delivery (CI/CD) pipelines.
- Observability & Supportability: We build observability into our service design, with all production services maintaining logs, common identifiers, defined SLOs and SLIs, and metrics for requests, errors, and availability.
Architecting for Massive Growth
Our updated architecture is built for tremendous growth. To date, we've already processed OVER 16 MILLION messages, conducted 1.5 MILLION surveys, and handled 400,000 messages EVERY SINGLE WEEK. With 21X revenue growth since 2021, our current investment strategy is focused on supporting and replicating this success at a hockey-stick growth trajectory.
Why Rust and Serverless?
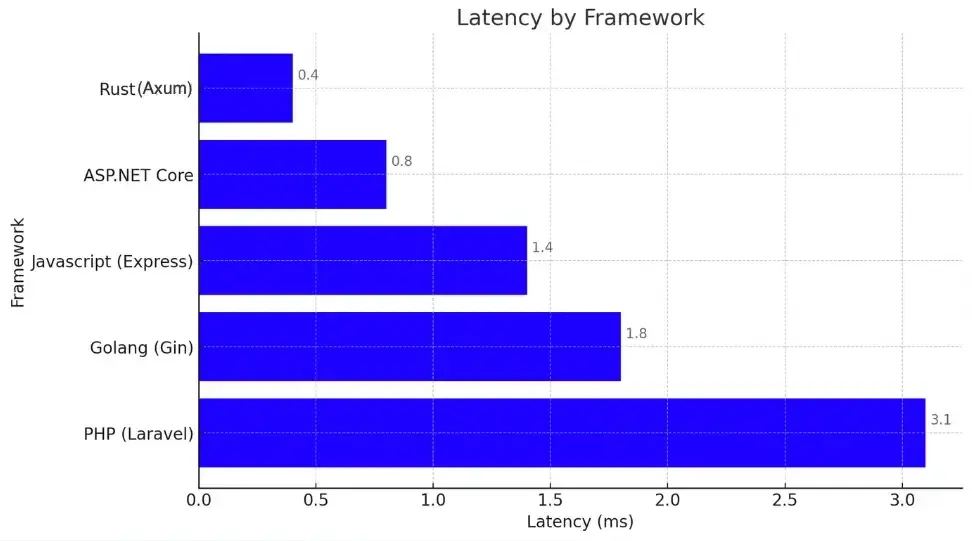
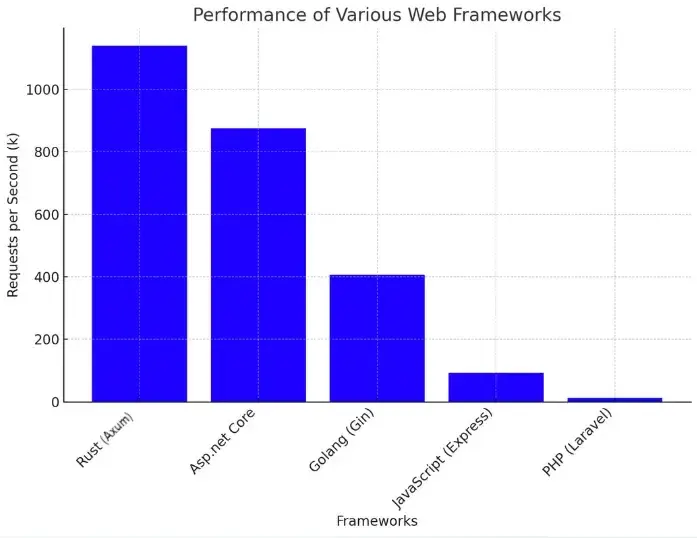
After evaluating POCs in three languages, we selected Rust running on a serverless architecture. This choice was driven by:
- Rust: A modern, type-safe language with compile-time error detection, a vibrant community, and excellent performance. Its asynchronous programming capabilities—particularly through libraries like Axum and Tokio—proved crucial for our high-throughput messaging system. Benchmarks demonstrated Rust with Axum handling over a million requests per second.
- Serverless: Deploying on Azure Functions lets us harness on-demand computing resources that scale automatically while keeping costs efficient.
Key Platform Components:
Serverless Functions: Each endpoint, queue trigger, and processor operates as a distinct serverless function.
Databases: We use Postgres for relational data, Cosmos DB for document storage (such as conversations), and Redis for caching.
Job System: A robust job system built on Azure Queues handles our offline processes, including bulk messaging, with automatic retry capabilities (dead letter queue - DLQ).
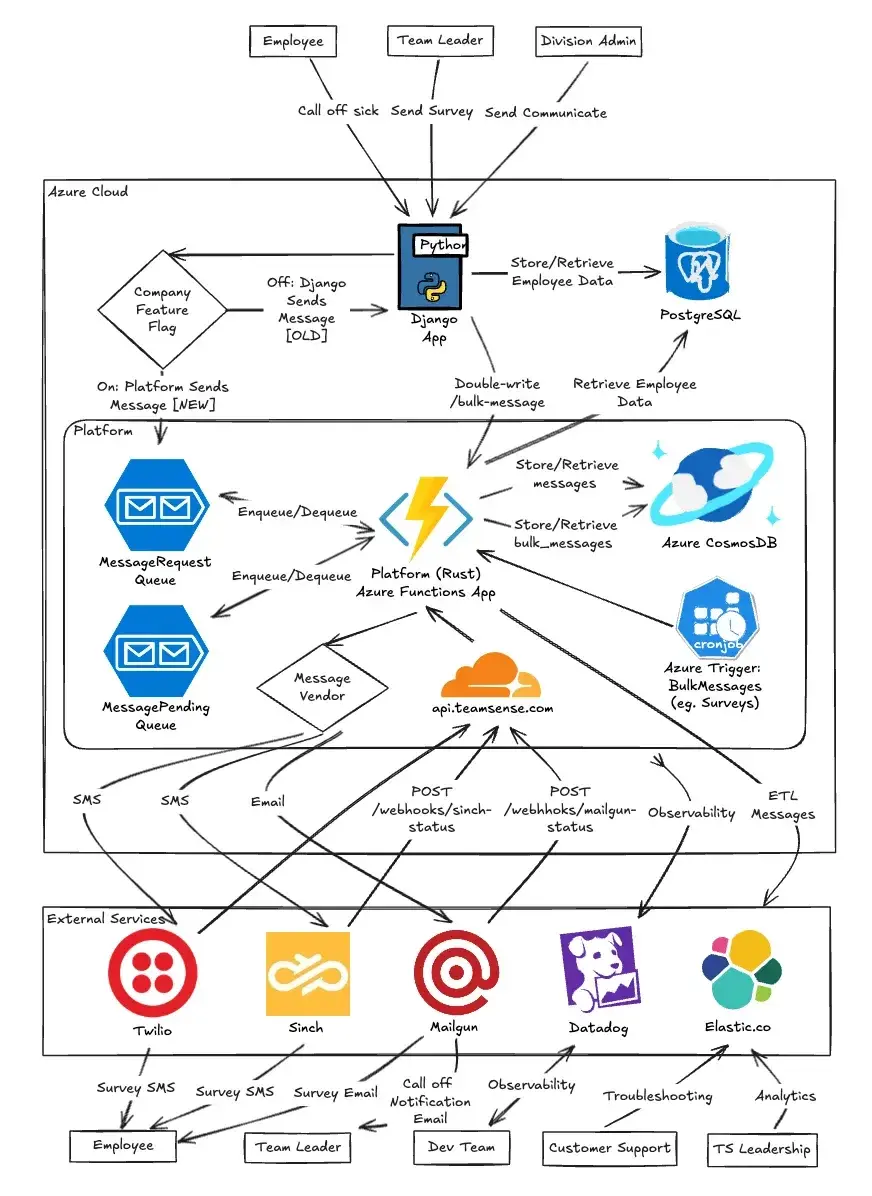
Messaging Flow:
Messages flow from our React front-end and SMS webhook calls through our existing Django app, which routes them to our new platform using message queues. When triggered, platform functions process these messages—performing database operations, integrating with external vendors (Twilio, Sinch, Mailgun), and handling logging and analytics.
Prioritizing Developer Productivity
Developer productivity lies at the heart of our platform. By streamlining development workflows, we accelerate innovation and enhance product quality. We've invested heavily in tools and processes that simplify local development, testing, and deployment.
Streamlined Local Development
To streamline local development, we've implemented several key commands and practices:
make watch: Compiles the platform with hot module reloading, allowing developers to see code changes reflected instantly in the running application. This reduces iteration time, improves feedback loops, and supports LLM integration changes.make test: Runs the entire unit test suite. This comprehensive testing ensures code changes don't introduce regressions and maintains high code quality, particularly when working with LLM features.make lint: Enforces consistent style guidelines and identifies potential performance bottlenecks, keeping our code clean, readable, and efficient.make start: Launches a simulated platform environment with local queues and timer triggers. Developers can test and debug in isolation, mimicking production conditions without affecting live systems—essential for testing asynchronous operations and event-triggered LLM agents.- Containerization: Docker containers provide consistent development environments, eliminating setup inconsistencies and simplifying the development process.
- Clear Documentation: Detailed documentation covers development workflows, API specifications, and best practices, enabling quick onboarding and effective contributions, especially for LLM agent deployments.
Collaboration
- Code Reviews: Code reviews are a vital part of our engineering culture at TeamSense. They go beyond checking syntax, conventions, and quality—these virtual review sessions are pure engineering learning magic. They're fun, intense, and embody everything we practice: agency, accountability, and autonomy.
Infrastructure and CI/CD
We utilize a robust CI/CD pipeline to automate our build, test, and deployment processes, ensuring rapid, reliable releases. Our infrastructure is managed as code, allowing us to create, modify, and destroy environments with ease and consistency.
- Terraform: Our infrastructure as code (IaC) uses Terraform to define and manage our Azure resources. This enables reproducible, rebuildable environments, ensuring consistency across development, staging, and production. We can track changes to our infrastructure in version control, allowing for auditability and rollbacks.
- GitHub Actions: GitHub Actions powers our CI/CD pipelines, orchestrating the entire process from code commit to production deployment. Our pipelines include:
- Code Validation: Automated checks for code quality and style.
- Linting: Using code style-checkers and Rust's famous "Clippy" to identify potential performance bottlenecks.
- Testing: Running our comprehensive unit test suite, ensuring code changes don't introduce regressions.
- Deployment to Staging and Production: Automated deployments to staging environments for testing, followed by carefully controlled deployments to production.
- Azure Deployment Slots: We utilize Azure Deployment Slots to facilitate blue/green deployments and zero-downtime swaps. This allows us to deploy new versions of our application without interrupting service, minimizing impact on our users. We can easily roll back to the previous version if needed, ensuring stability and reliability.
Observability with Datadog
We have implemented a comprehensive observability strategy using Datadog to gain deep insights into our platform’s performance, health, and behavior. Our goal is to detect and resolve issues proactively, ensuring a seamless user experience.
- Logs: We implemented structured logging to collect rich contextual logs with tracing information to enable swift error investigation. Our logs include metadata such as request IDs, user IDs, and service names, making it easier to trace issues across multiple components.
- Traces: Request-level tracing allows us to pinpoint bottlenecks and performance issues. We can visualize the flow of requests through our system, identify slow or failing components, and optimize performance. Distributed tracing helps us understand the dependencies between different services.
- Monitors: We set up real-time alerts to Slack and our pager service BetterStack for critical platform issues and queue backlogs. Monitors trigger when specific thresholds are exceeded, such as high error rates, latency spikes, or queue depth increasing. These alerts enable our team to respond quickly to potential problems.
- Dashboards: We use Datadog dashboards to maintain real-time visibility into system health. Our dashboards include metrics such as latency, error rates, API performance, and database metrics. We can monitor the performance of individual serverless functions, message queues, and other components, providing a holistic view of our platform.
- LLM Observability: Our LLM/Agentic AI monitoring covers several critical aspects:
- Topic Analysis: Monitoring the topics being processed by our LLM agents to ensure accuracy and relevance.
- Latency Metrics: Tracking the response times of our LLM agents to identify performance issues.
- Security Measures: Monitoring for potential security vulnerabilities, toxicity, or misuse of LLM agents.
- Comprehensive Input Evaluation: Evaluating the inputs received by our LLM agents to ensure they are valid and appropriate, and the LLM response is appropriate.
- Model Performance: Tracking metrics to determine the current performance of each LLM and alerting when there is performance degradation.
These observability practices allow us to maintain a reliable, high-performing platform and quickly address any issues that arise.
Conclusion
Our technical decisions have enabled us to build a scalable, secure, and adaptable attendance management platform. These architectural choices and principles will continue to guide our development, ensuring we deliver the best possible experience for our customers and are ready for future growth and innovation.
About the Authors
James Stafford

Mitchell McKenna, Principal Software Engineer
15+ years building high-performance, scalable web application backends. Mitch thrives on mentoring engineers, pushing the boundaries of technology, and delivering industry-leading solutions.
